DSpark: speculative decoding that pays off
June 10, 2026
Last month I wrote about MTP and ended on a catch.
Speculative decoding only pays off if the model accepts the tokens it drafts. Draft three, reject two, and you have added work instead of removing it.
DeepSeek’s DSpark is the cleanest answer to that catch I have seen.
Parallel drafters like DFlash write a whole block of tokens in one forward pass. Fast, because drafting cost stops scaling with block length. But every position is predicted independently. No token knows what the others picked. So the model turns “of course” into “of problem”, and acceptance falls apart toward the end of the block.
Autoregressive drafters like Eagle3 do the opposite. Each token conditions on the last one, so the block stays coherent. But latency grows with block size, which forces them shallow and short.
DSpark keeps the heavy parallel backbone and bolts a lightweight sequential head onto it.
The backbone does the expensive work in one pass. The sequential head is tiny, a low-rank Markov layer that nudges the next token based on the one before it. Once position one samples “of”, it boosts “course” and suppresses “problem”.
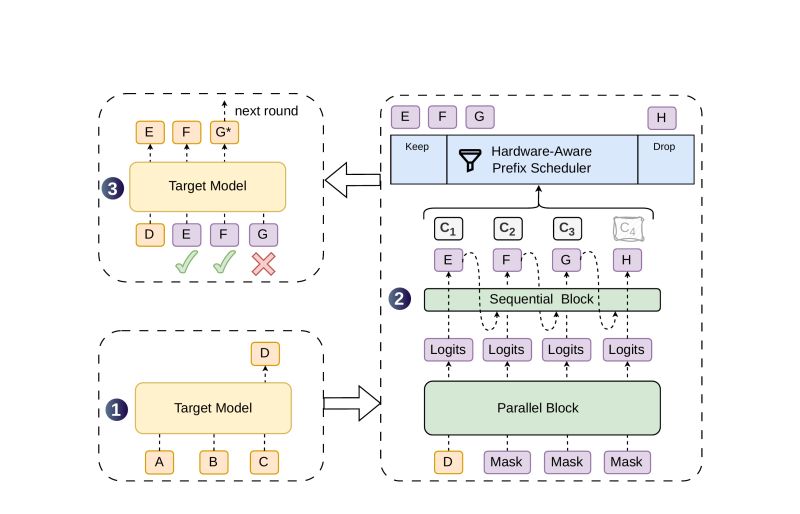
The trade is good:
The second idea is the one I think matters more in production.
A confidence head predicts the chance each drafted token survives verification. A scheduler then decides how many tokens to actually verify, per request, based on live server load.
Light load, verify more, the extra tokens are basically free. Heavy load, prune the low-confidence tail before it eats batch capacity other users need.
So the speculation budget becomes a scheduling decision, not a fixed knob.
The 400% number doing the rounds is misleading, and DeepSeek says so in the paper. The 661% and 406% figures sit at strict latency targets where the old baseline basically falls over. They call it evidence of extending the frontier, not a representative speedup.
At matched throughput, the real gain is 57–85% faster generation per user.
A few more caveats:
Which is the answer to the catch I opened with.
DeepSeek ran single-token MTP-1 in production, not MTP-3 or 5, because a static multi-token drafter tanks throughput under load. That is the exact failure I described in the MTP post. DSpark makes the draft length adaptive instead of static, so larger blocks stop being dangerous.
And they open-sourced the training framework, DeepSpec, with checkpoints for Qwen and Gemma, not just DeepSeek. You can train a drafter for a model you actually run.