Attention over the layers
May 28, 2026
Every Transformer has attention over tokens. None had attention over their own layers.
That just changed.
Kimi (Moonshot AI) published Attention Residuals. It fixes something that’s been an unexamined default since ResNet.
Residual connections add every layer’s output into one running total with equal weight. No selectivity. No input-dependence. Layer 3’s representation and layer 97’s are blended the same way.
With PreNorm (what every major LLM uses), this running total grows unboundedly with depth. Each layer’s relative contribution shrinks as more layers pile on. Deeper layers are forced to produce increasingly large outputs just to stay influential.
This is what it’s called. You can prune the last half of a deep network’s layers with barely any performance drop. Those layers were contributing almost nothing.
Replace fixed accumulation with learned attention over depth. Each layer gets one small learned parameter that lets it attend over all previous layer outputs, weighted by content similarity. It learns which earlier layers matter for the current input. Initialized to behave like standard residuals, then learns to specialize during training.
For production scale: Block AttnRes groups layers into ~8 blocks. Standard residuals within blocks, attention only across block summaries. Drastically lower memory cost.
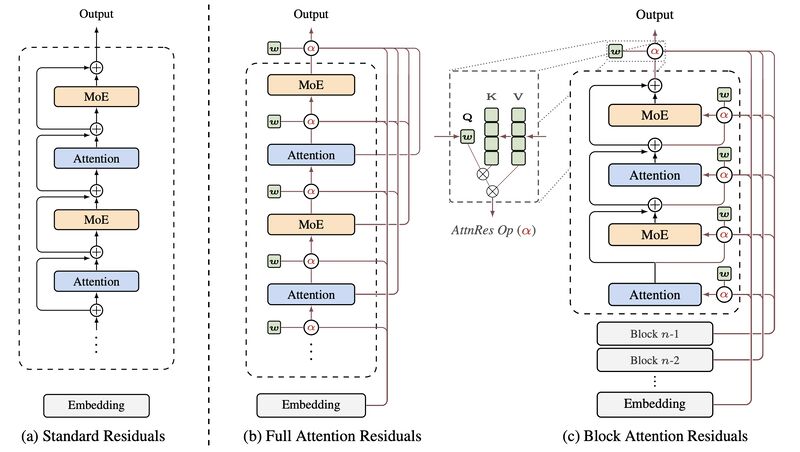
The paper shows that standard residuals are actually performing depth-wise linear attention. Highway Networks are depth-wise linear attention with gates. AttnRes is depth-wise softmax attention.
The exact same progression that happened on the sequence axis.
This isn’t just Kimi. DeepSeek has Hyper-Connections. Every major AI lab is independently attacking the Curse of Depth.
This works because language is inherently structured. On unstructured data, standard residuals can actually win. Real gains, not universal.
Residual connections haven’t changed since 2016. One learned vector per layer getting you 25% compute savings tells you how much room is left in Transformer architecture.
The race isn’t just about scale anymore. It’s about wiring.
Paper, Attention Residuals, Kimi Team (arXiv: 2603.15031)